
Google Protobuf 真的是万能的嘛 ?
最近在使用RPC框架开发后台Server,RPC默认将协议数据通过Protobuf进行封装。大多数场景下,这样做都没啥问题。然而,我们Server使用RPC框架后,数据处理延时增长了2倍。
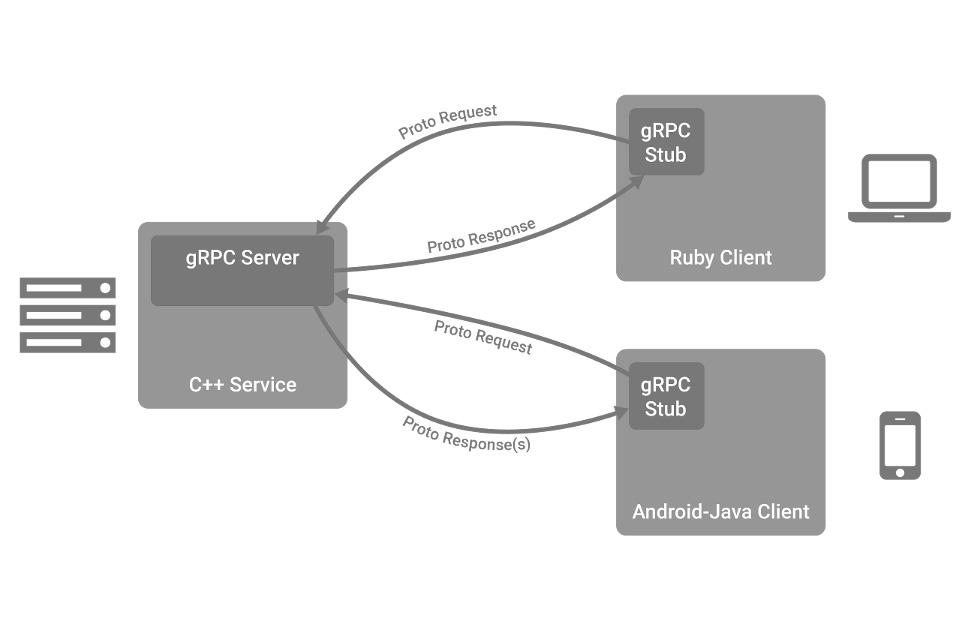
- Server要将收到的1080p数据转码成720p格式,再返回给client。
- client会对源数据进行分块,每块大小保持在5MB左右。
- client和Server均处于内网环境,几乎不会发生丢包。
对于这种问题,通常的做法就是逐段分析处理耗时情况。经过分析发现,发送端调用RPC接口发送数据,花费了3.6 ms。顺着代码往下看,就发现RPC内部直接调用了协议的序列化接口,将协议和数据打包后发送。
问题很明显,在定义协议的时候,虽然数据data使用的是bytes,还是会进行序列化。按照常规思路来想,bytes 已经是二进制格式,在Protobuf里面无非多一次内存拷贝,不会带来这么大的性能开销,协议格式如下。
message RpcCompressRequest {
string objcet_name = 1;
uint32 slice_offset = 2;
uint32 slice_num = 3;
string compress_params = 4;
bytes data = 5;
}
实践是检验真理的标准,在同一台机器上运行两组client和server,一组client发送用bytes表示的二进制数据,并通过Protobuf序列化字符串。另外一组直接发送二进制数据。在两组的server上统计收到全部数据所需要的时间,PB序列化的数据要进行反序列化。
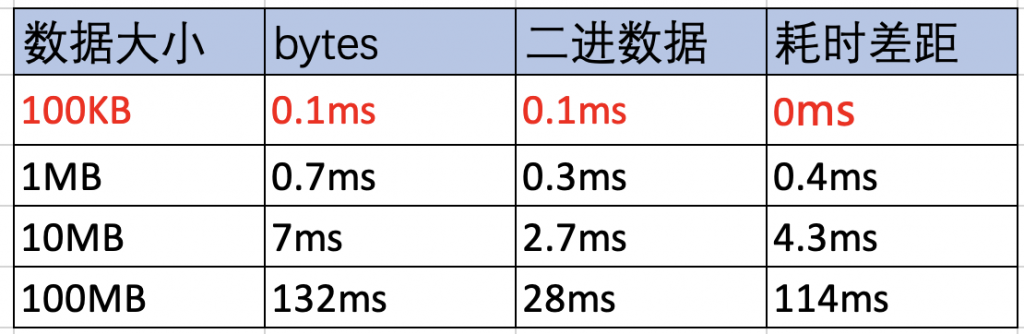
- 小数据100KB以下,使用Protobuf编解码和直接发送二进制数据,耗时接近,PB带来的影响几乎没有。
- 数据超过1MB以上,使用Protobuf编解码是直接发送二进制裸数据的两倍以上,数据越大,使用Protobuf耗时越久。
- 同机不同进程通过socket 发送大块数据,也会带来传输延时,可采用更优方式。
产生上述问题的原因,是我们使用Protobuf的方式不对,大块数据不应该使用Protobuf进行序列化。大块数据传输应该直接使用二进制。Protobuf在协议封装上,也具有很多优势。
- Protobuf 支持多平台、多语言,前后版本兼容性强。
- 和XML、JSON格式相比,Protobuf占用空间少,保存速度快,比XML小3到10倍,速度快20到100倍。
- Protobuf 协议格式规范,类似于C语言里面的结构体,结构清晰、可读性强。
- 工具健全,官方提供协议生成工具,支持多语言。
结合上述优势以及实际业务中的使用、网络上的资料来看, Protobuf主要使用在以下场景。
- 用于IPC/RPC通信,用于Client 和Server,Server之间信令(结构化数据)协议的序列化/反序列化。
- 用于数据存储领域,将某些数据结构信息进行序列化,保存到内存或者磁盘上,等待需要时进行恢复。例如将VoIP通话中的房间信息保存到共享内存,防止进程意外重启丢失房间信息。
解决问题,找到原因,总结经验是每一个打工人都应该具备的能力。这次问题的直接原因是Protobuf适用错误,根据原因是按照常规思路设计协议,有疑问时缺乏验证,不熟悉Protobuf适用场景。技术人对于每一个疑问,还是要刨根问底,多问自己几个为什么。
接下来将要分享后台协议设计的一些关键点,关注个人公众号,获取最新消息。
{kind=link}