一次内存异常引发半夜加班带来的思考
最近有个relay模块在线上进行紧急发布,一共600台机器半天之内发布完成。晚上6点开始手机就开始持续震动,realy模块信令都出现异常,用户进房间失败率突增。监控曲线上跑出了一个凹字形。赶紧回退realy模块恢复业务,同时开始紧急定位问题原因。

后台服务采用特定框架进行开发,在回退的过程中发现有部分进程出现coredump导致进程没有被拉起来属于回退失败。分析coredump文件发现,是core在一个共享内存初始化的地方,这次变更并没有修改这个地方的代码。因此,这里不是根本原因,只是表面现象。

现在主要是尽快恢复业务,把进程拉起来。既然是共享内存初始化失败,如果把共享内存释放掉,理论上来进程就可以拉起来,可以正常提供服务。找到共享内存的key,执行如下命令。
- ipcrm -M 0x499602d2;
- ipcrm -M 0x499602d3;
- ipcrm -M 0x499602d4;
- ipcrm -M 0x499602d5;
通过发布变更系统,把程序回退到上一个稳定的版本。把这个共享内存删除后,进程立刻就拉起来,服务恢复正常。验证这个方法无异常后,就开始制定版本回退计划。为了减少对用户的影响,我们只能在晚上11点进行回退,停进程-> 清理共享内存->重新拉起进程。半夜12点半现网600台机器全部重新拉起,手机震动声终于停了。
根据上述堆栈可以明确这是个内存问题,第一现场大概率不是上面这个堆栈。进一步分析崩溃堆栈发现还有一处core,出现了数据越界现象。这个现场极有可能是导致本次崩溃的根本原因。

从最等层堆栈来看,问题出现在memcpy触发了系统保护,导致进程被系统结束掉。从最底层到最上层堆栈的调用顺序都是正常,没有出现堆栈异常现象,所以大概率是这个cache函数引发的问题。
利用GDB下的命令 frame和print 输出不同堆栈运行时各个变量的值,发现有个一个buff出现out of bound提示,那这个问题就是由于memcpy时访问了非法的内存地址,触发操作系统发出SIGSEV 信号出现段错误(segmentation fault)。下一步就需要分析这个致命buff的由于以及可能触发越界的原因。
这个buff用来缓存收到的数据包,供接收端请求重传。它是一个固定大小的内存池,在进程启动后直接new出来一大片空间,按照配置初始化内存单元。
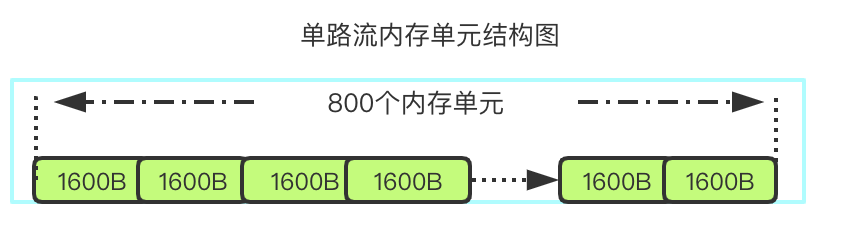
后台relay模块有4个进程运行,单个进程要支持2000用户并且每个用户有2路流。那么就需要开辟 1.6k * 800 * 2 * 2000 * 4 共20G的内存,平均每个进程5G内存,而线上提供服务的机器为千兆机器8核16G内存。
经过上述计算,内心一阵窃喜。昨晚问题的原因就是因为分配的内存空间超过物理内存空间大小,而又由于操作系统的虚拟内存机制在进程启动时没有发生异常,只有在运行的过程需要发生写内存时才出现崩溃。至于要清理共享内存才能拉起来,大概率是因为共享内存的内存空间被写入异常数据,导致open 共享内存key之后读取数据出现异常触发系统保护。
通过这次线上异常,深刻领悟到当线上出现异常时不要慌,快速定位出是哪里的变动引起的,优先通过回退、调度剔除等运营手段恢复业务,不能影响用户,后续可通过保留的现场进行问题定位。在开发的过程,对于每个配置项的修改,都要能评估出这样修改带来的影响是什么,避免盲目上线。
接下来就借此次线上异常问题分析虚拟内存与共享内存之间的对应关系,欢迎关注。
One thought on “一次内存异常引发半夜加班带来的思考”
网页图片要是能放大,看起来会更舒服一些